
Automated Evaluation of Scientific Writing Shared Task 2016
The vast number of scientific papers being authored by non-native English speakers creates a large demand for effective computer-based writing tools to help writers compose scientific articles. Several shared tasks have been organized (Dale and Kilgarriff, 2011; Dale et al., 2012; Ng et al., 2013; Ng et al., 2014), constituting a major step toward evaluating the feasibility of building novel grammar error correction technologies. English language learner (ELL) corpora were made available for research purposes (Dahlmeier et al., 2013; Yannakoudakis et al., 2011). An extensive overview of the feasibility of automated grammatical error detection for language learners was conducted by Leacock et al. (2010). While these achievements are critical for language learners, we also need to develop tools that support genre-specific writing features. The shared task focuses on the genre of scientific writing.
The goal of the Automated Evaluation of Scientific Writing (AESW) Shared Task is to analyze the linguistic characteristics of scientific writing to promote the development of automated writing evaluation tools that can assist authors in writing scientific papers. The task is to predict whether a given sentence requires editing to ensure its 'fit' within the scientific writing genre.
A few words should be said about the evaluation of scientific writing. Some proportion of ‘corrections’ in the shared task data are real error corrections (such as wrong pronoun, as well as various other grammatical and stylistic errors), but some almost certainly represent style issues and similar ‘matters of opinion’. And it seems unfair to expect someone to spot these. This is because of different language editing traditions, experience, and ... the absence of uniform agreement of what ‘good’ language should look like. Nevertheless, your participation in the shared task will certainly help spotting the characteristics of ‘good’ scientific language, and help create a consensus of which language improvements are acceptable.
References
- Daniel Dahlmeier, Hwee Tou Ng, and Siew Mei Wu. 2013. Building a large annotated corpus of learner English: The NUS Corpus of Learner English. In Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications, pages 22–31, Atlanta, GA, June.
- Robert Dale and Adam Kilgarriff. 2011. Helping Our Own: The HOO 2011 Pilot Shared Task. In Proceedings of the Generation Challenges Session at the 13th European Workshop on Natural Language Generation, pages 242–249, Nancy, France.
- Robert Dale, Ilya Anisimoff, and George Narroway. 2012. HOO 2012: A report on the Preposition and Determiner Error Correction Shared Task. In Proceedings of the Seventh Workshop on Building Educational Applications Using NLP, pages 54–62, Montreal, Canada.
- Claudia Leacock, Martin Chodorow, Michael Gamon, and Joel Tetreault. 2010. Automated Grammatical Error Detection for Language Learners. Morgan and Claypool.
- Hwee Tou Ng, Siew Mei Wu, Yuanbin Wu, Christian Hadiwinoto, and Joel Tetreault. 2013. The CoNLL-2013 Shared Task on Grammatical Error Correction. In Proceedings of the Seventeenth Conference on Computational Natural Language Learning: Shared Task, pages 1–12, Sofia, Bulgaria.
- Hwee Tou Ng, Siew Mei Wu, Ted Briscoe, Christian Hadiwinoto, Raymond Hendy Susanto, and Christopher Bryant. 2014. The CoNLL-2014 Shared Task on Grammatical Error Correction. In Proceedings of the Eighteenth Conference on Computational Natural Language Learning: Shared Task, pages 1–14, Baltimore, MD, USA.
- Helen Yannakoudakis, Ted Briscoe, and Ben Medlock. 2011. A new dataset and method for automatically grading ESOL texts. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 180–189, Portland, OR, USA.
Task Objective and Definition
The objective of the AESW Shared Task is to promote the use of NLP tools to help ELL writers improve the quality of their scientific writing.
The main goals of the task are
- to identify sentence-level features that are unique to scientific writing;
- to provide a common ground for development and comparison of sentence-level automated writing evaluation systems for scientific writing;
- to establish the state-of-the-art performance in the field.
- automated writing evaluation of submitted scientific articles;
- authoring tools for writing English scientific texts;
- filtering out sentences that need quality improvement.
The goal of the task is to predict whether a given sentence needs language editing to improve it. The task is a binary classification task. Two types of predictions will be evaluated: binary prediction (False or True) and probabilistic estimation (between 0 and 1).
Registration
You need to formally register in order to obtain the training, development and test data. After registration you will be invited to join the aesw2016@googlegroups.com newsgroup to see discussions and to receive further information of the Shared task. To register, please send the following information to aesw@googlegroups.com:
- Name of institution or other label appropriate for your team
- Name of contact person for your team
- E-mail address of contact person for your team
Important: Registration will close on
Send your registration again if you do not get any response within two working days.
Important dates
Website and team registration for participation in AESW 2016 Shared Task opened. Training and Development data released. | ||
Registration is closed. | ||
Test data released. | ||
|
| Deadline for submitting system results. |
Results released. | ||
Deadline for submitting team reports. | ||
Revisions of team reports sent. | ||
Deadline for final version of team reports for proceedings. | ||
Shared Task Presentations at the BEA 11 Workshop |
All deadlines are 11:59PM Pacific Time.
The Data Set
The data set is a collection of text extracts from 9,919 published journal articles (mainly from physics and mathematics) with data before and after language editing. The data are based on selected papers published in 2006--2013 by Springer Publishing Company and edited at VTeX by professional language editors who were native English speakers. Each extract is a paragraph that contains at least one edit done by the language editor. All paragraphs in the dataset were randomly ordered from the source text for anonymization.
Sentences were tokenized automatically, and then both text versions -- before and after editing -- were automatically aligned with a modified diff algorithm. Some sentences have no edits, and some sentences have edits marked with
The training, development and test data sets are comprised of data from independent sets of articles.
- The training data
- The development data: The development data will be distributionally similar to the training data and the test data with regard to the edited and non-edited sentences, as well as the domain.
- The test data: Test paragraphs retain texts tagged with
<del> tags and the tags are dropped. Texts between<ins> tags are removed. However, all edits of test data will be provided after submission of system results.
Shared Task participating teams are allowed to use other publicly available data. Teams will not be able to use proprietary data. Use of other data should be specified in the final system report.
You can download the data set here.
Supplementary Data
To speed up data preparation for training, development and testing, the following supplementary data will be accessible to all participants:- Training, development and test data split into text before editing and text after editing:
- Tokenized sentences with sentence ID at the beginning of the line.
- POS tags of sentences with sentence ID at the beginning of the line.
- CFG trees of sentences with sentence ID at the beginning of the line.
- Dependency trees of sentences with sentence ID as the first line of each tree.
- Texts from Wikipedia articles (the dump of Apr 2015):
- Tokens
- POS tags
- CFG trees of sentences
- Dependency trees of sentences
The data are processed with the Stanford parser with the following parameters:
- model: englishRNN
- JAVA code for grammatical structure: GrammaticalStructure gs = parser.getTLPParams().getGrammaticalStructure(tree, Filters.acceptFilter(), parser.getTLPParams().typedDependencyHeadFinder());
- type: typedDependencies
Write us if you would like to share your data as a supplementary data.
Detection score
We will measure the detection score of sentences that need improvement, i.e., were edited by language editors. The score will be an F-score of sentences that need improvement. The score will be computed for both tracks individually.
-
For the boolean decision track, a gold standard sentence Gi is labeled "improve" if there is an edit that spans part of Gi. We calculate a system's Precision (P) as the proportion of sentences correctly labeled "improve" (i.e., that have edits in the gold standard):
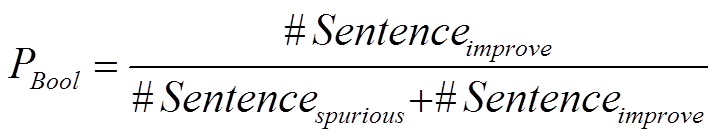
Similarly, Recall (R) will be calculated as:

The detection score is the harmonic mean (F-score):
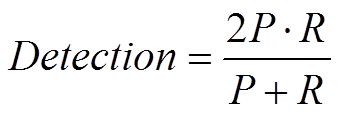
-
For the probabilistic estimation track, the mean squared error (MSE) will be used. A gold standard sentence Gi is assigned 1 if it has edits, and 0 if it does not have edits. Systems will predict the probability that each sentence needs improvement, and we calculate Precision as the MSE of the sentences Ei that were predicted as `needs improvement', i.e., their estimated probability is above 0.5:
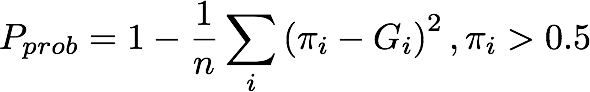
Similarly, we calculate Recall as the MSE of the sentences Gi that have edits in the gold standard:
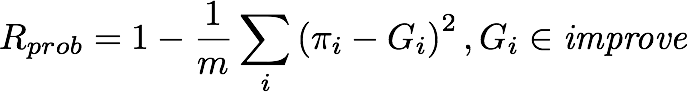 ,
, where, πi is Probabilistic Estimation, G is Gold Standard, n is the number of sentences predicted as 'need improvement', and m is the number of gold standard sentences that need improvement.
The harmonic mean Detectionprob has the same calculation as Detectionbool. The higher the Detectionprob, the better is the system.
Participating teams are allowed to submit up to two system results for each track, i.e., participants can submit results many times but only the last two submissions will remain in the server. In total, a maximum of four system results will be accepted from each team. All participating teams are encouraged to participate in both tracks.
Submission format
The predictions of the test data-set should have the following format:
- For the Binary prediction task:
- <sentenceID><tab><True|False><new line>
- e.g., 9.12\tTrue\n
- <sentenceID><tab><True|False><new line>
- For the Probabilistic estimation task:
- <sentenceID><tab><Real number><new line>
- e.g., 9.12\t0.75212\n
- <sentenceID><tab><Real number><new line>
Codalab.org
We use Codalab.org for the result submission. The AESW 2016 Shared Task competition remains open for the post-competition submissions and results reproducability. The competion can be found here.
Report submission
Participating teams must submit a shared task paper describing their system. The report should be 4-8 pages long and contain a detailed description of the system and any further insights. Teams are encouraged to submit the source of their report along with PDF document to help reviewers in revising and editing the report.
All system papers should be presented in the poster session at the BEA11 workshop .
Shared Task papers must follow the same format, style and length guidelines as the BEA11.
Submission system: We will use the same Softconf START submission system used for the workshop papers. Please follow the BEA11 workshop link and login with your START account.
Organizing Committee
Vidas Daudaravicius (primary contact at "vidas dot daudaravicius at vtex dot lt")
VTeX Solutions for Science Publishing
Rafael Banchs
Institute for Infocomm Research
Elena Volodina
University of Gothenburg
Courtney Napoles
Johns Hopkins University